Trust Engine
Kolide Fleet and osquery Overview
Authorization to sensitive resources require confirmation that the user is who they say they are and that their activities on the company computer are considered normal behavior. Authentication begins with the user entering their credentials to log into the company website. But what if the user's credentials were stolen? This is where the Trust Engine steps in by regularly ingesting data from the company issued device and processing that information into a trust score that can authorize or deny users for access to a secured application.
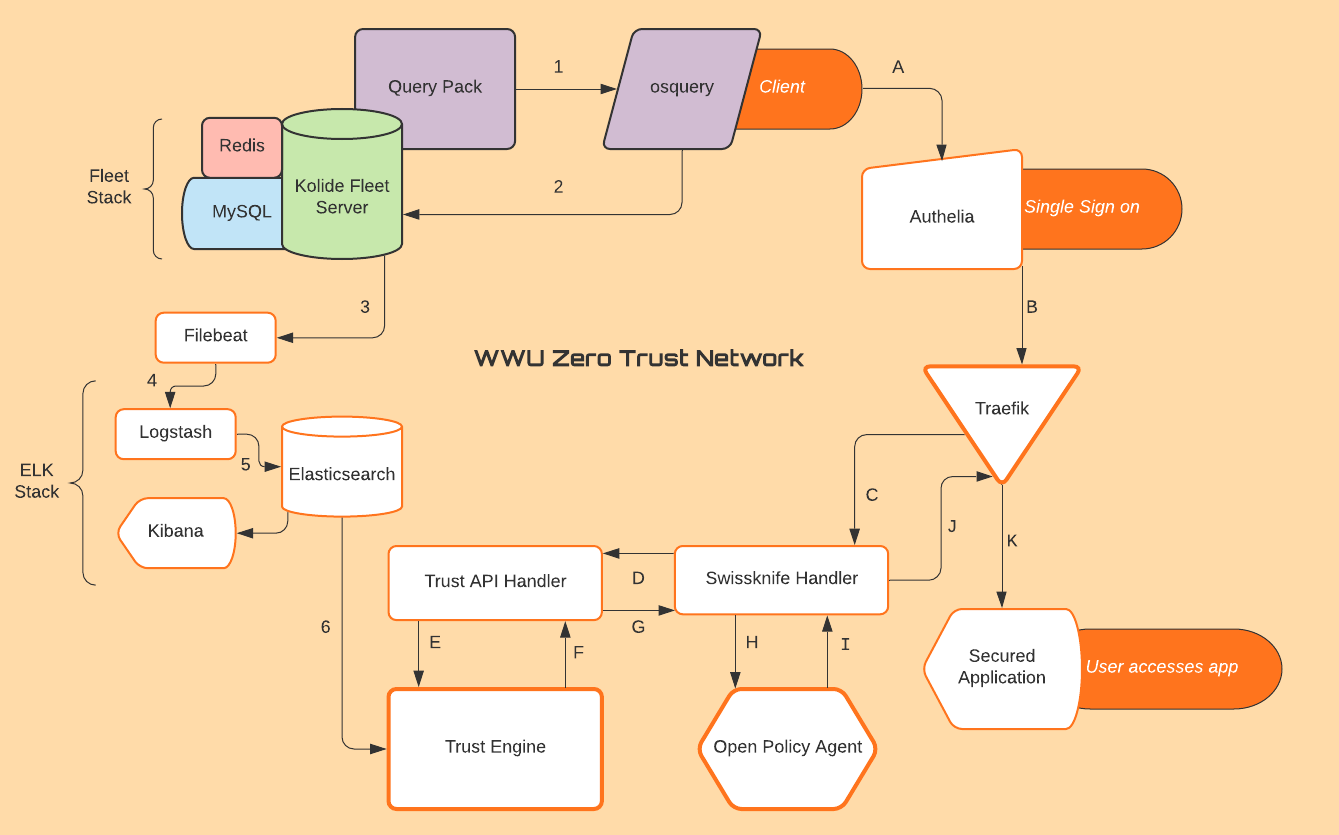
The client machine is preinstalled with osquery, a tool that turns computer information into a relational database. A few additional configurations are need as well to enable the client to transmit data to the Kolide Fleet server. The Kolide Fleet server is a tool used for managing a fleet of clients installed with osquery. Fleet can monitor if clients are active, its version of osquery, and enable query packs to run on clients.
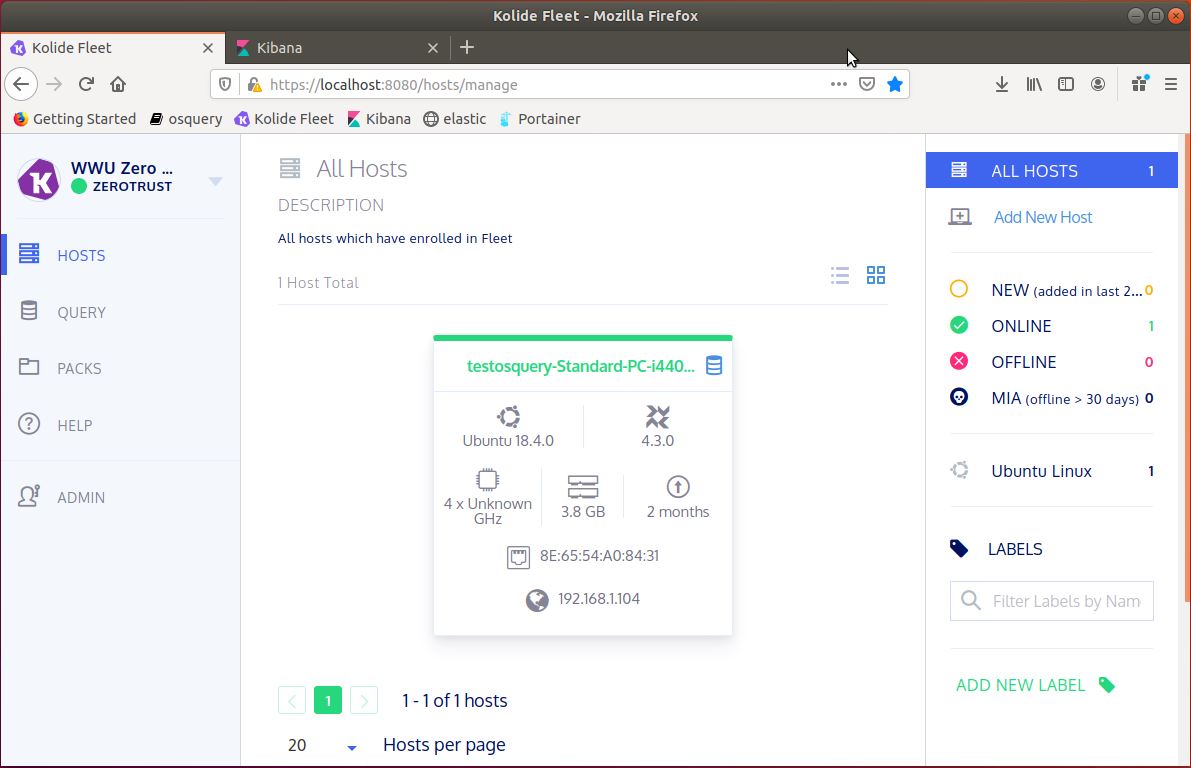
These query packs consist of one or more queries that use pre-built osquery tables to output information about the computer such as active users or running processes. Fleet retrieves the data from the queries run on the clients and then stores the data using Redis and MySQL. We chose these tools because of osquery's ability to quickly produce computer information from a simple query and deliver that information in JSON format.
ELK Stack and Trust Engine Overview
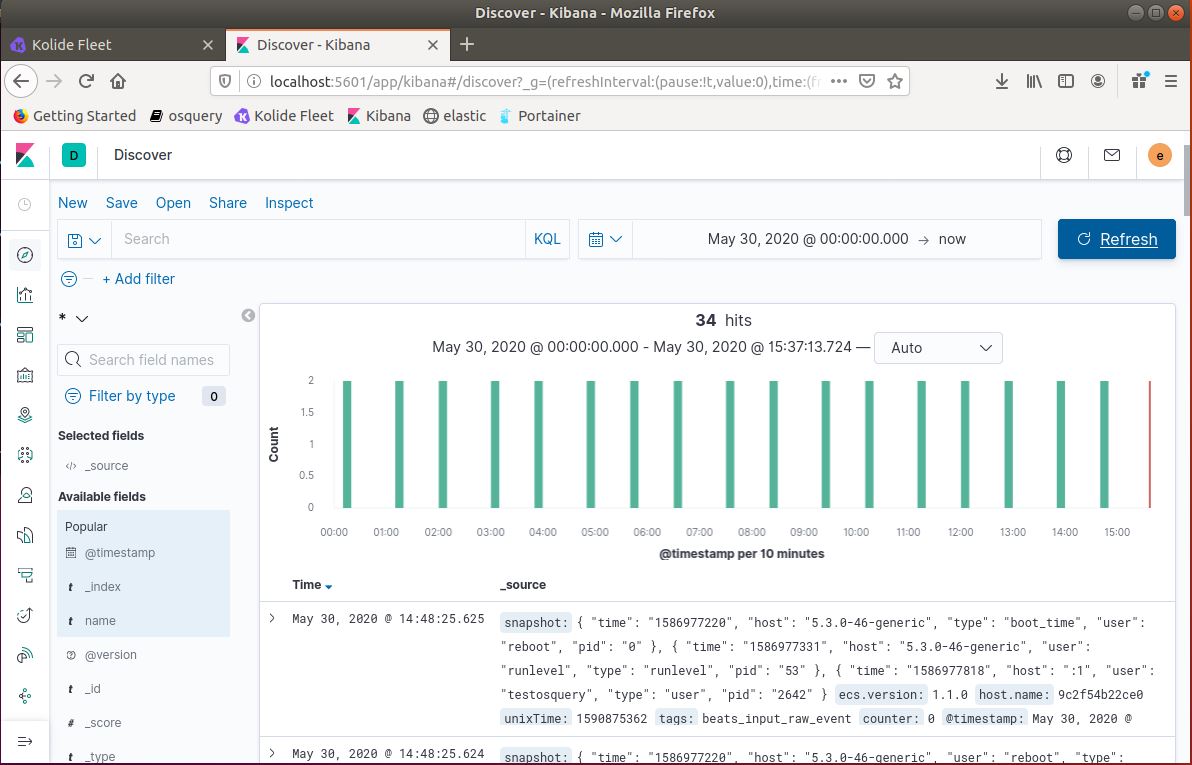
The ELK Stack consists of Logstash, Elasticsearch, Kibana, and in addition Filebeat. When packaged together these applications take in, aggregate, and hold the osquery data received from the client. This data, in JSON format, is then available for user interact and view on Kibana. The Kibana dashboard interface displays the logs received from the TestOsquery machine.
A simple GET request of the index can return detailed information about incoming query logs.
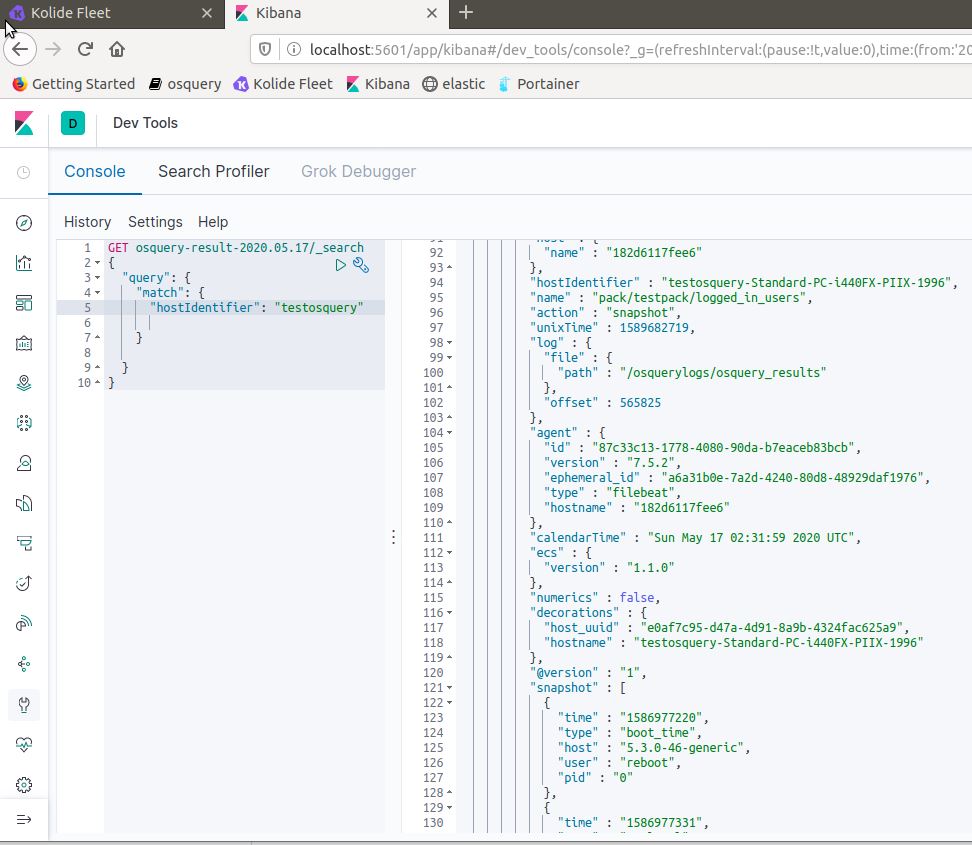
The ELK Stack acts as a collecter and organizer of osquery data so that the Trust Engine can with ease make queries against Elasticsearch.
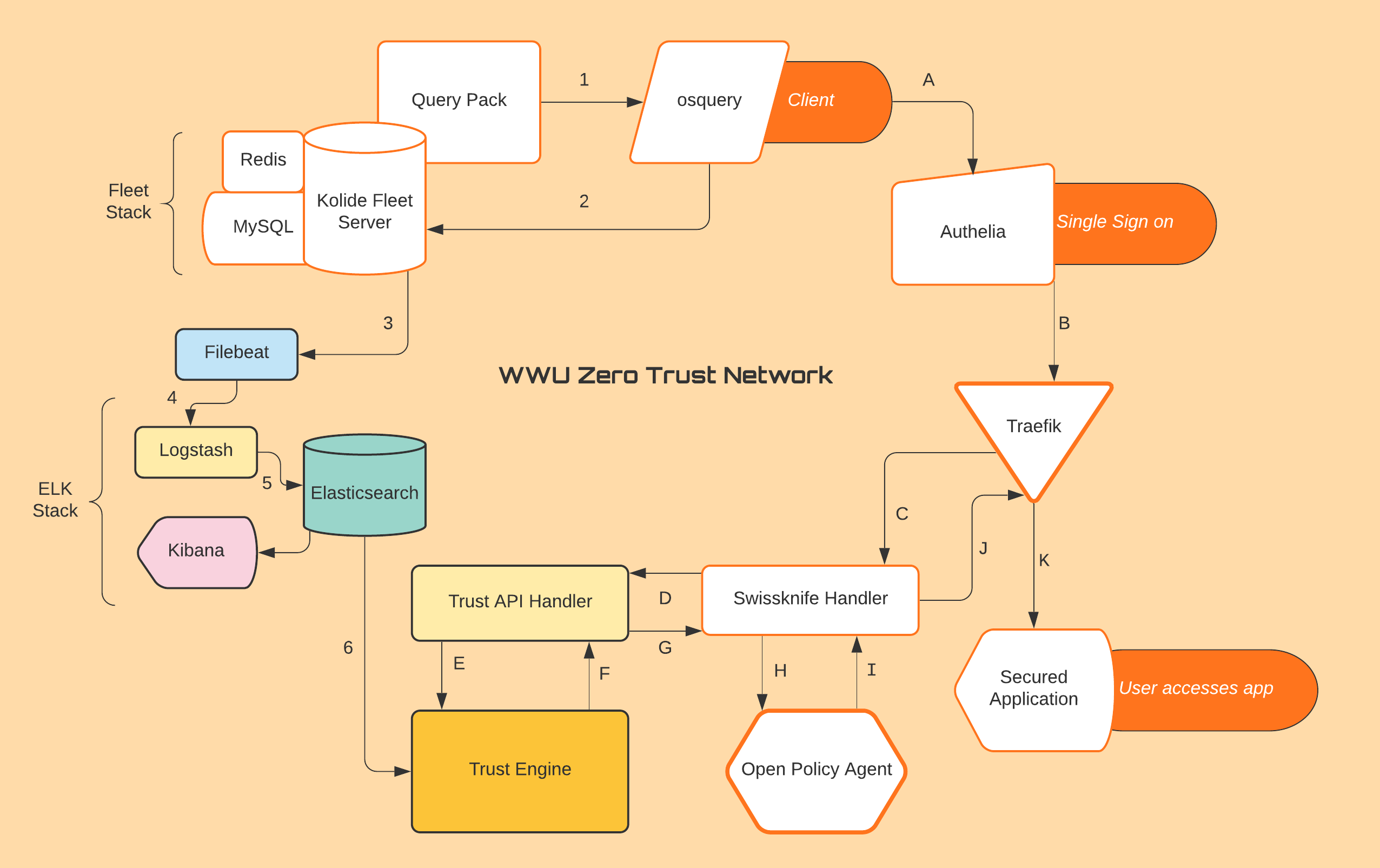
The Trust Engine's job is to create a trust score. This trust score works in unison with Open Policy Agent to either allow or deny a user access to a secured application. The Trust Engine takes in JSON format Elasticsearch data and parses it in order to identify the data related to user seeking access. Here are the steps taken between Elasticsearch, Trust Engine, and the Trust API Handler:
- The Trust Engine is on standby waiting to hear from the Trust API Handler to get the username.
- Once the Trust API Handler receives a username from the Swissknife Handler via a PUT request, the Trust Engine starts calculating a score.
- The Trust Engine using elasticsearch_dsl package (a tool to easily build queries for Elasticsearch), grabs the latest query stored in Elasticsearch related to the the request specified in the query. The first part of the query filters by the username received from the Trust API Handler. Next the query is set to match anything from the osquery pack, 'testpack’. Last, only the 'snapshot' data field is returned from the query.
- The 'snapshot' data arrives in JSON format and regex is used pull the string data from the fields into lists. One of these queries may contain an array of information. Those arrays and their subsequent fields are each parsed. For instance, the query that contains information of logged in users may have recorded 3 different users from one computer.
- The data from the lists are then compared to lists of data deemed normal and expected. If there is match, then the score increases for that specific field. If there is not match, then the score decreases. This is done for every field of data attributed to the user. Those multiple field scores are added up to create a trust score.
- The trust score is then sent to the Trust API Handler, and the Trust API Handler pushes it to the Swissknife Handler.
The table below shows our initial thought process when devising how the trust engine score would be calculated. The the left Table column represents osquery tables and the information from the tables that we considered important for processing a trust score. We chose these fields because they presented a complete view of the information and sections that we deemed important. Some of these fields have an atomicity of 'no' or 'yes', which means we expect some of this information to always be the same such as the kernel information, but not necessarily the same for logged in users. In order to create a structured scoring engine, we decided to break up the aggregation of scores into three sections: User, Device, and Application. Each of them we consider equally important when collecting information. These three sections can add up to 33, and when all added together total 99, with a rounding of 1 to create a high score of 100.
| User | Devices | Application | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Table | Column | Score | Atomicity | Table | Column | Score | Atomicity | Table | Column | Score | Atomicity |
| logged_in_users | type | 20 | no | kernel_info | version | 10 | Managed (NO) | Browser Fingerprint | 50 | no | |
| user | 20 | no | device | 15 | no | processes | pid | 15 | yes | ||
| host | 20 | no | arp_cache | Address | 10 | yes | name | 35 | no | ||
| time | 10 | yes | Mac | 15 | no | state | 15 | yes | |||
| pid | 10 | yes | os_version | name | 20 | no | uid | 35 | no | ||
| sid (windows) | 20 | no | version | 14 | Managed (NO) | total = 100 | application = 50 | ||||
| total = 100 | user = 33 | patch | 13 | Managed (NO) | |||||||
| time | weekday | 10 | yes | platform | 20 | no | |||||
| year | 10 | yes | codename | 13 | Managed (NO) | ||||||
| month | 10 | yes | install_date | 20 | no | ||||||
| day | 10 | yes | total = 100 | devices = 25 | |||||||
| hour | 10 | yes | system_info | hostname | 14 | no | |||||
| minutes | 10 | yes | uuid | 16 | no | ||||||
| seconds | 10 | yes | not in Linux? | hardware_vendor | 14 | no | |||||
| timezone | 30 | no | not in Linux? | hardware_model | 14 | no | |||||
| total = 100 | user = 33 | not in Linux? | hardware_serial | 14 | no | ||||||
| users | uid | 20 | no | computer_name | 14 | no | |||||
| gid | 20 | no | local_hostname | 14 | no | ||||||
| username | 20 | no | total = 100 | devices = 25 | |||||||
| uuid | 20 | no | |||||||||
| type | 20 | no | |||||||||
| total = 100 | user = 33 | ||||||||||
| Final User Score: 100 | Final Device Score: 100 | Final Application Score: 100 | |||||||||
Now, our scoring system currently doesn't use all of this information above either because we found the fields to not be useful or because of time constraints implementing them. We intend to expand the information we use in the future for scoring, but for now this table is a good overview on how the collective scores create one final trust score.